
Neurelo - a new way of working with databases

When modeling a domain I’m going to write software to handle, I always start with the data. Whether I plan to write a small standalone app or work with a team on a system with moving parts handled by different people, I always find it easiest to orient myself by thinking about two things: what data am I trying to handle, and where do I need it to be? Starting with this gives me insight to what constraints I need to handle, which gives me a jumping-off point for whatever I design. Do I have a lot of users in different locations, or will there only be a single location the data ends up needing to be accessed from? If I need to support users across different locations, does all of the data need to be consistent for all of them? Maybe I know that some of the data won’t be shared across multiple users, or maybe it’s okay for some parts of it to lag behind a bit for some users. When someone changes their password, I definitely don’t want there to be any race conditions where the old password is still viable for any amount of time, but if someone reacts to a comment with an emoji, I probably don’t need to worry as much if there’s a brief window where some people might not see the reaction on the comment right away.
The main benefit of this exercise for me is helping me consider the question of “What am I trying to do?” separately from “How am I going to do it?” Without that separation, I’ve found it easy to fall into a pattern where I focus too much on the “how” rather than the “what”, and the actual problem I’m trying to solve gets further and further from view to the point where I’ve lost sight of my original goal. By focusing on the higher-level details of what needs to be done, I’ve often found that the answer to the “how” question becomes clear on its own.
Knowing the answer to the “how” question isn’t where the work ends, though; I still have to make it! Sometimes this ends up being the most tedious part of a project; I know what I want to do, and I know how I want to do it, but translating that from a design to software I can run and maintain means writing a lot of code, and not the kind that’s always fun. Too often, I get to spend less time on the interesting, unique parts of what I’m trying to solve and more time dealing with low-level details like “how do I efficiently get this data from point A to point B?” and “what does the data need to look like when viewed at point B?” Lots of tools exist for storing data, and all of them have their own ways of getting data out of them. I’ve personally spent a lot of my career working on tools that boil down to “get data out of this specific type of storage”; I previously worked at MongoDB for several years on their drivers for various languages, and more recently I spent a few years at AWS working on client software for their cloud-based service for hardware security modules. Querying and using data requires different boilerplate depending on what database and programming language you’re using.
Over the years, I’ve often thought about what a general solution for this problem would look like. In the vein of Larry Wall’s “Three Virtues” of a programmer, which an early mentor of mine with years of experience in Perl shared with me, I wanted to be lazy and impatient rather than settle for the same boilerplate being written over and over, and I had the hubris to want the solution to be good enough for everyone, not just me. While looking for job opportunities last fall, I stumbled upon a fairly young startup called Neurelo that seemed to be inspired by a lot of the same ideas I had. My first conversation with them felt like serendipity; they had seen the same patterns that I had everywhere, concrete ideas on what solving would look like, and ample progress on implementing a lot of those ideas. Although there were details to work out before I was ready to join, in hindsight it’s clear that I was hooked, and I can’t imagine an outcome other than hopping onboard to work with them. I’m genuinely excited by what we offer developers, not just in terms of what we can give, but in terms of what we don’t take in order to provide our features.
What is Neurelo?
The core concept of Neurelo is providing a layer of services on top of a database without managing it directly; developers bring their own database (MongoDB, MySQL, and PostgreSQL are supported presently), and Neurelo keeps track of the schema and provides APIs for accessing it. Neurelo’s schema tooling supports introspection, manual editing (via either JSON schema or a visual UI), and each version of the schema is checked into a git repo that you can either manage externally or have created behind the scenes for you. Similar to editing the schema, migrations can be both generated automatically from the schema and edited manually as needed. At the click of a button, you can deploy a server that provides fully documented REST and GraphQL APIs along with generating SDKs for various languages for interacting with them. Beyond that, there’s an in-browser playground to try out changes before deploying, custom API endpoints for complex queries, multiple CI/CD environments, schema-aware mock data generation, and more.
Version Controlled Schema
One of Neurelo’s core features is the easy management of schema evolution over time. Database schemas are represented in a JSON schema format we call a “metaschema” – a (JSON) schema for defining (database) schemas. Schemas can be crafted and edited in multiple ways:
Raw JSON/YAML
Visual editor
AI prompting (Text-to-Schema)
You can freely switch between these methods while defining or updating your schema. Changes made with one method are immediately reflected in the others. For example, you can introspect an existing database to infer the current schema, use the AI prompt to propose a change, view it in the visual editor, manually adjust as needed, then commit the schema and share it with a coworker for further testing.

Each version of a schema is stored in a Git repository. When you create a project, you can either provide an external Git repo for Neurelo to utilize or have one created and managed for you. You aren’t tied to any specific Git hosting service; whether you use GitHub, GitLab, another service, or host your projects on a personal server; you just need to provide a URL and permissions via either SSH or HTTPS.
Neurelo also includes a built-in ERD viewer for visualizing the schema, which is a great way to get a high-level view of the data model being used without any distractions.

Autogenerated REST/GraphQL API
Because the schema contains the necessary information to read or write to the database, Neurelo can automatically launch a server providing access via either REST/JSON or GraphQL. Each entity in the schema has endpoints for CRUD operations with common options like filtering, projecting, recursive lookup, or creation of related entities. Once you commit a schema, you can deploy a live version of the server in Neurelo for your application to use instead of directly connecting to the database. An API playground is also available for testing and building out your API and SDK calls.
Importantly, the database access code isn’t hidden when using the auto-generated APIs; each endpoint provides a “query visualization” option, showing the raw query executed alongside the response.

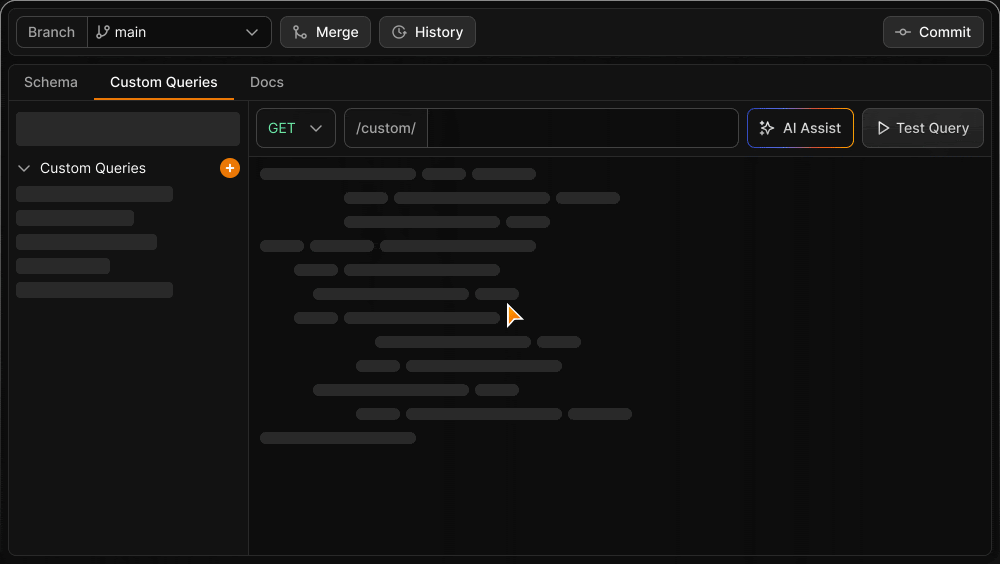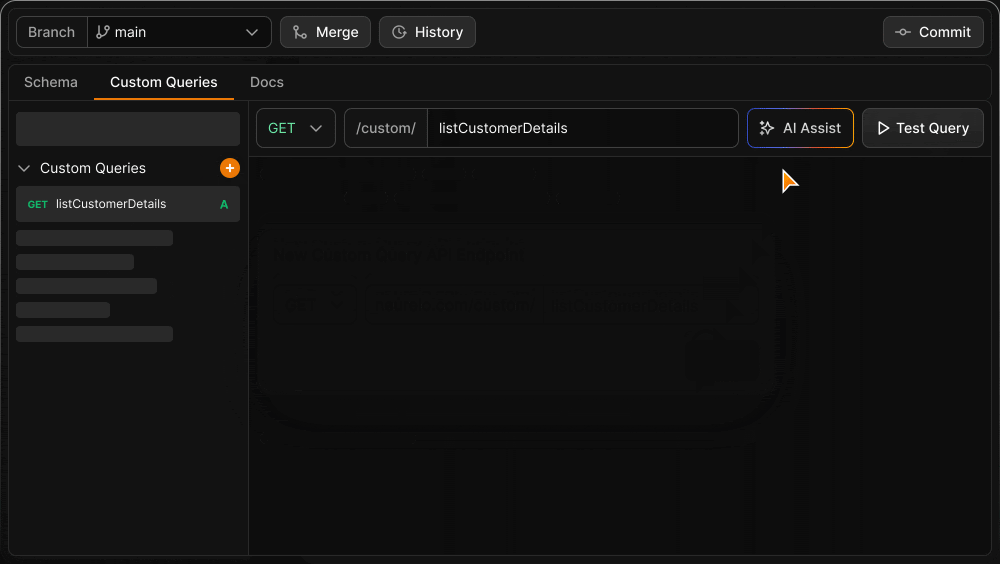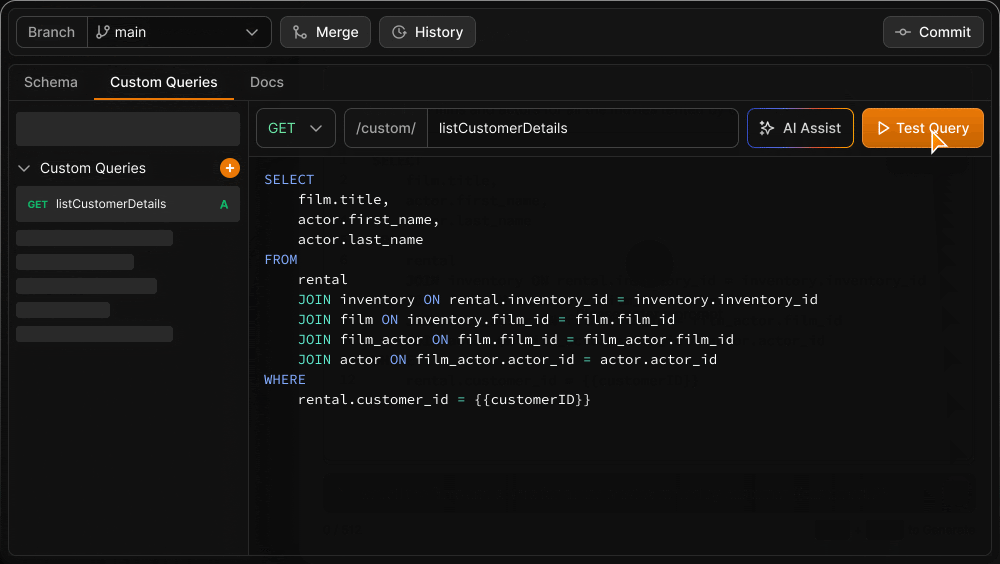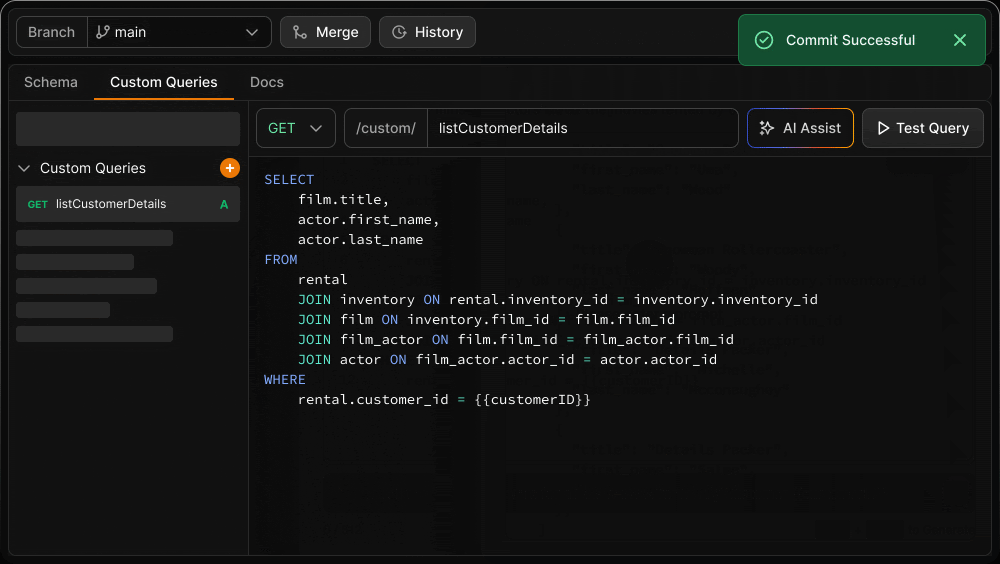
Custom Query Endpoints
In addition to the automatically generated API endpoints, you can define and test custom endpoints using raw queries with the native syntax of your database. Custom queries are version controlled alongside the schema, ensuring you always have a complete version of the API your application used if you need to roll back.
Custom queries are a key part of the theme of how we make sure that you can retain full, fine-grained control over any or all of your queries without forgoing the benefits of using schema version control and a database-agnostic API. Combined with the ability to observe the raw query executed by any autogenerated endpoint, you can review query efficiency and replace it with a custom query if necessary.
Additional Features
Comprehensively covering everything Neurelo can do would be overkill for this overview, but a few other features are worth calling out:
Multiple environments, e.g. separate prod/staging/dev for a given project
Access control rules for fine-grained control over what CRUD operations on individual tables/collections are available to a given API key
Mock data generation to make it easier to try out various operations with a schema in a dev/test environment
Flexible Hosting Options allowing you to choose between hosting API servers on Neurelo, managing them in your own cloud, or running them locally for development and testing needs
Not Just Another ORM
Some of the features described above might sound similar to the benefits that are offered by ORMs; for example, automatic generation of high-level abstractions to wrap database queries and the ability to check models in version control are both things an ORM can provide you as well. This isn’t accidental; Neurelo is designed with similar goals of improving developer experience around user databases, but we also strive to avoid many of the common pitfalls that occur when using ORMs in real-world development.
Transparency
One way that some ORMs often cause friction is the lack of transparency in how queries are actually resolved. While being able to query by describing the objects to get from the database can be powerful, it’s not always intuitive how this will actually translate into a raw database query. This can lead to the infamous “N + 1” query problem, where multiple database calls are used to obtain the set of results rather than combining all of the logic into a single query.
Neurelo provides several features to mitigate this issue. As mentioned above, every auto-generated API endpoint gives the developer the ability to obtain the raw query used under the hood. Rather than trying to mask the lower-level database details, Neurelo intentionally gives developers the ability to leverage their SQL/MQL knowledge to verify that queries are efficient. Combined with the ability to define custom endpoints with raw queries, developers can have full control over the exact queries being executed.
“Non-Leaky” Abstraction
Although many ORMs provide the ability to “drop down” into a raw query for performance reasons, it comes at the cost of the benefits of using an ORM; instead of being able to cleanly abstract the database-level logic from the higher-level application code, using a custom query with an ORM requires lifting the database logic into the codebase.
Neurelo’s custom queries don’t suffer from the same issue. Your database access abstraction remains clean – using APIs. Custom queries are defined alongside the schema and kept in the same version control, and changes to them are decoupled from changes to the application. If you optimize a custom query to return the same results more efficiently, the application code won’t need to change, which means you won’t need to redeploy your application.
AI as a (very) helpful assistant
One remaining feature of Neurelo only tangentially referenced above is our suite of integrated AI tools to help make defining schemas, queries and using APIs easier. AI assistance is opt-in and available when needed. For example, you can prompt the AI with instructions like “define a schema for a restaurant” or “write a query to retrieve all employees hired in the last month.” AI tools generate output in the same format you could define manually, allowing you to modify the schema or query as needed.
Significantly, AI is only used as a tool to help define schemas and custom queries; autogenerated API endpoints use queries generated deterministically based on the schema, and no AI is used when executing operations received by the API server. AI is only used as a tool at the step where schemas and custom queries are defined, and even then only when explicitly invoked by the user.
What makes Neurelo different?
As important as technical details are, they’re only part of what makes me so excited about Neurelo. What’s unique to me about Neurelo is how intentional we are in trying to avoid certain patterns that wouldn’t be beneficial to users—even ones that might make our lives as the ones developing Neurelo easier.
Using a third-party software product always comes with the risk of vendor lock-in. The benefits of any product, especially a “service” product like Neurelo, needs to be weighed against the potential cost of needing to migrate in the future for any number of possible reasons (e.g. degradation of quality, failure to grow with additional needs, untenable increase in pricing). It’s not reasonable to ask customers to blindly trust a software vendor, and even a well-intentioned provider can’t feasibly guarantee that future owners will continue acting in good faith.
To that end, Neurelo’s approach to mitigating fears of vendor lock-in is to provide concrete ways for users as insurance against future issues, and where possible, to allow users to decide for themselves how much to “hedge” their investment in using Neurelo. All of our design decisions stem from a keen awareness of this issue. We chose to represent schemas in a format defined by JSON schema, a widely-used open standard in part because we know that users can interact with it using existing tooling if they stop using Neurelo in the future. Similarly, using your own git repo to store the schema history and migrations gives you full control over what happens to it if you leave; removing our access to the repo only requires revoking an access token or ssh key, and you can freely track the changes in another git remote that we don’t have access to (or even treat that remote as the source and sync the changes “downstream” to the repo we’ve been granted access to). You don’t need to trust that we won’t cut your access off to your schemas when you can make it impossible for us to do that! We use a “bring-your-own-database” model rather than managing your database ourselves so that nothing stops you from deciding to cut off our access if you decide to migrate away in the future. Query transparency not only helps you diagnose and rectify performance issues, but it lets you hedge against needing to rewrite all of your query logic if you aren’t sure you’ll stick with Neurelo. It would be impossible to completely eliminate any sunk costs, but we’ve gone out of our way to reduce them across the board; we want people to use Neurelo because they want to, not because they have to!
Ultimately, giving users this level of control is why I’m not shy about suggesting that people try out Neurelo. While I think that what we’re offering is worth it from a technical standpoint, I also know that my bias from working on it means that people shouldn’t blindly trust my opinion. My genuine enthusiasm doesn’t mean I think people shouldn’t be skeptical about adopting something that claims to solve such a large problem. My hope is that you will be skeptical, and your expectations will be high, but you’ll give Neurelo a shot anyways; I really think that it will be useful for a lot of developers out there. If you do, I’d be thrilled for you to hear any feedback, good or bad, so feel free to reach to email sam@ (on the .com domain linked to throughout this article)!